JPCERT/CC が公開したフィッシングサイトのリストから Amazon に似せた URL を抽出してみた.
こんにちは.あらい大先生です.
先日,JPCERT/CC がフィッシングサイトの URL のリストを公開しました [1, 2].
一般人がフィッシングサイトに狙ってアクセスするのは難しいため,データセットの公開はありがたいです.
また,個人的な興味として,
フィッシングサイトの URL は本物と似せていると聞くが,それは本当か?
がありました.
そのため,このデータセットを用いて,Amazon を騙るフィッシングサイトの URL の傾向を調べてみることにしました
結果だけを知りたい方は コチラ をクリックしてください.
手順
以下の手順で調査しました.
- CSV ファイルから Amazon を騙るフィッシングサイトの URL のみを抽出する.
- 複数の CSV ファイルから URL を抽出する.
- URL と amazon との類似度を評価する.
CSV ファイルから Amazon を騙るフィッシングサイトの URL のみを抽出する.
まずはデータセットをダウンロードします.
Google Colaboratory では,先頭に ! が付いた文字列を Linux コマンドとして解釈して実行してくれます.
そのため,git clone コマンドを利用すると良いでしょう.
!git clone https://github.com/JPCERTCC/phishurl-list.gitダウンロードが完了したら,試しに CSV ファイルを読み込んで出力してみましょう.
import pandas as pd
df = pd.read_csv('./phishurl-list/2022/202206.csv')
dfダウンロードできていれば,以下のような出力が得られます.
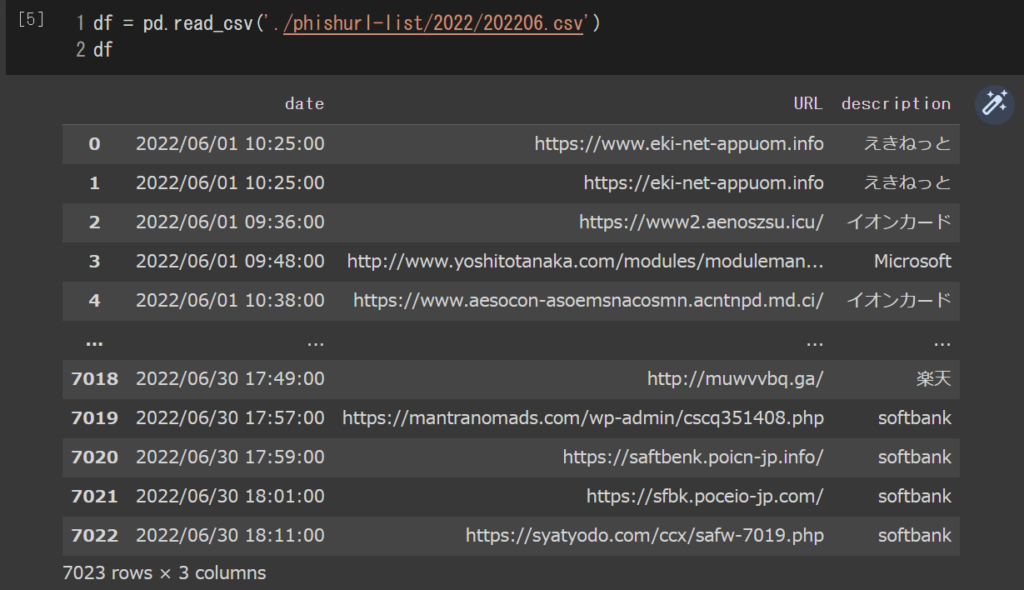
[1, 2] と画像 1 より,URL 列にはフィッシングサイトの URL,description の列には騙られたブランドの名称が記載されています.
今回は Amazon を騙るフィッシングサイトの URL のみを抽出する必要があります.
URL のみを抽出したいときは以下のように書きます.
df['URL']このように,[] の中に抽出したい列名を指定します.
また,description が Amazon の行を抽出したいときは以下のように書きます.
df[df['description'] == 'Amazon']このように,[] の中に検索条件を指定します.
この 2 つを組み合わせることで,Amazon を騙るフィッシングサイトの URL のみを抽出することができます.
df[df['description'] == 'Amazon']['URL']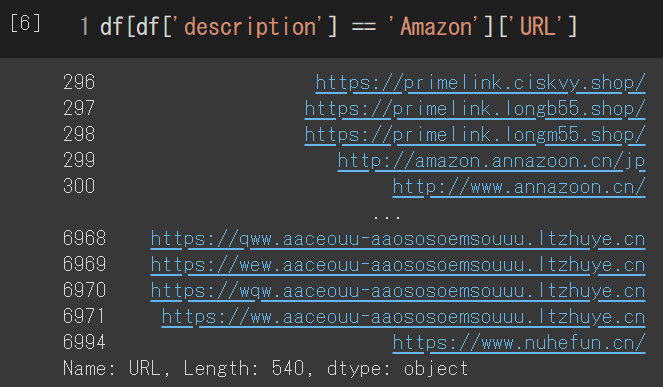
また,list(df[df['description'] == 'Amazon']['URL']) と list() で囲むことで,list 型のデータに変換することができます.
複数の CSV ファイルから URL を抽出する.
先ほどは,1つの CSV ファイルから Amazon を騙るフィッシングサイトの URL を抽出しました.
次は,全ての CSV ファイルから抽出できるようにします.
import pathlib
url_list = []
for path in pathlib.Path('phishurl-list').glob('./20*/*.csv'):
df = pd.read_csv(path)
url_list += list(df[df['description'] == 'Amazon']['URL'])Pathlib は os.path や glob といったファイル操作に関するモジュールを1つにまとめたモジュールです.
6 行目の in 以降で,phishurl-list ディレクトリの配下の,’20’ で始まるディレクトリの配下の,CSV ファイルのパスのイテレータを取得しています.
ParserError: Error tokenizing data. C error: が発生する場合
pd.read_csv('phishurl-list/2019/201910.csv')を実行すると,以下のエラーが発生しました.
ParserError: Error tokenizing data. C error: Expected 3 fields in line 51, saw 4https://github.com/JPCERTCC/phishurl-list/blob/main/2019/201910.csv で 51 行目のデータを確認すると,URL の中に ‘,’ がありました.
この ‘,’ を区切り文字と解釈してしまい,「この CSV ファイルは date, URL, description の3列で構成されていそうなのに,51行目には4列目のデータがあるよ」というエラーが起きていると思われます.
試しに ‘,’ を削除してみると,エラーは発生しなくなりました.
URL と amazon との類似度を評価する.
本物の Amazon の URL は https://www.amazon.co.jp/ です.
おそらく,多くの方は URL を正確に記憶しているわけではなく,「たぶん amazon という文字列はあると思う」くらいの曖昧さで記憶していると思います.
また,最近のブラウザには,http や https,www を省略する機能が搭載されています.
そのため,省略された URL と 'amazon' との,標準化されたレーベンシュタイン距離 (Normalized Levenshtein Distance) で類似度を評価することにしました(レーベンシュタイン距離については,[3] の説明が参考になります).
標準化されたレーベンシュタイン距離の実装を以下に示します.
!pip install python-LevenshteinGoogle Colaboratory にはレーベンシュタイン距離を算出するためのモジュールがインストールされていないので,pip コマンドでインストールしています.
import Levenshtein
def nld(str1, str2):
return round(Levenshtein.distance(str1, str2) / max(len(str1), len(str2)), 3)4 行目の Levenshtein.distance(str1, str2) で,2つの文字列とのレーベンシュタイン距離を算出します.
標準化されたレーベンシュタイン距離を算出するには,先ほど算出したレーベンシュタイン距離を,2つの文字列のうちの長い方の文字列の長さで割る必要があります.
そのため,Levenshtein.distance(str1, str2) / max(len(str1), len(str2) と書いています.
徐算によって小数が得られるので,round(X ,3) を実行して X を小数第3位までの概数にしています.
import re
re_pattern = re.compile(r'^https?://(www.)?')
sim_list = []
for url in set(url_list):
sim_list.append((nld('amazon', re.sub(re_pattern, '', url.rstrip('/'))), url))3 行目の re_pattern = re.compile(r'^https?://(www.)?') で,URL から 'https://www' ('s' が無いこともあります) を省略するための正規表現パターンをコンパイルしています.
5 行目の set(url_list) で,url_list の中で重複する要素を削除しています.
7 行目の re.sub(re_pattern, '', url.rstrip('/')) で,URL の先頭の 'https://www' と末尾の '/' を削除しています.
その後,'amazon' と省略された URL との標準化されたレーベンシュタイン距離と,元の URL のタプルを sim_list へ保存しています.
最後に sim_list をDataFrame に変換します.
pd.DataFrame(sim_list, columns=('nld', 'URL')).sort_values('nld', ascending=True)amazon に似た URL を知りたいので ascending = True と指定し,標準化されたレーベンシュタイン距離 (nld) が小さい順になるように出力させます.
上手くいくと,以下のような出力が得られます.
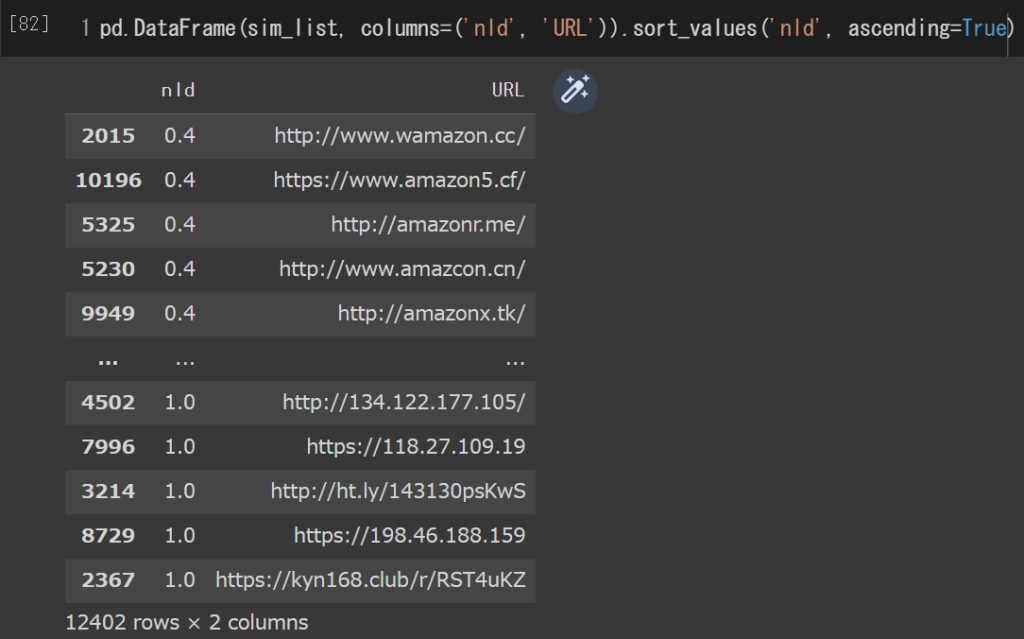
結果
画像 3 のように出力された評価結果から,上位 20 個の URL を抜粋してみました.
(注) 全て Amazon のフィッシングサイトです!
- http://www.wamazon.cc/
- https://www.amazon5.cf/
- http://amazonr.me/
- http://www.amazcon.cn/
- http://amazonx.tk/
- https://www.amazon5.ga/
- http://www.amazoen.cn/
- https://amazonz.cc/
- http://amacon.co/
- https://www.amavon.cc/
- https://www.amaznn.cc/
- http://www.amazun.jp/
- http://www.amazmo.jp/
- https://www.amazno.me/
- http://www.amazooon.co/
- http://www.amazzon.icu/
- http://www.amazonn.icu/
- http://www.amazonp.top/
- http://www.amazonzn.cc/
- https://anmazon.biz/
雑な考察ですが,amazon の後ろに 1 文字を追加した URL と,on 辺りを別の文字に置換した URL が多いみたいです.
また,SSL/TLS 証明書が無い(https 化されていない)フィッシングサイトも少なくないみたいです.
Let'Encrypt や Comodo による SSL/TLS 証明書を持つフィッシングサイトが多いという記事 [4] を読んだことがあったので,意外な結果でした.
画像 3 の評価結果の CSV ファイルは,以下からダウンロードできます.
おわりに
Amazon を騙るフィッシングサイトの URL を調べてみました.
その結果,やはり本物と似せていました.
Web ページの見た目も似せていると思われるので,一般の人々がフィッシングサイトか否かを判別するのは難しそうです.
無理に判別するのではなく,ブックマーク(お気に入り)に,よく利用する Web サイトを登録しておき,そこからアクセスするように心がけると良いでしょう.
参考
- 一般社団法人 JPCERT コーディネーションセンター:JPCERTCC/phishurl-list: Phishing URL dataset from JPCERT/CC,GitHub,入手先〈https://github.com/JPCERTCC/phishurl-list/〉(参照 2022-10-07).
- 一般社団法人 JPCERT コーディネーションセンター:,JPCERT/CCが確認したフィッシングサイトのURLを公開,JPCERT/CC Eyes,入手先〈https://blogs.jpcert.or.jp/ja/2022/08/phishurl-list.html〉(参照 2022-10-07).
- Ishio:文字列間の類似性を測るための『標準化』編集距離の計算方法について,Qiita,入手先〈https://qiita.com/Ishio/items/d52b9221c92bd4ebb344〉(参照 2022-10-07).
- Netcraft:Let's Encrypt and Comodo issue thousands of certificates for phishing,Netcraft News,入手先〈https://news.netcraft.com/archives/2017/04/12/lets-encrypt-and-comodo-issue-thousands-of-certificates-for-phishing.html〉(参照 2022-10-08).
